Fascinating Deepseek Tactics That May help Your Small Business Grow
페이지 정보

본문
 The post-coaching facet is much less revolutionary, however gives more credence to these optimizing for online RL coaching as DeepSeek did this (with a type of Constitutional AI, as pioneered by Anthropic)4. The $5M figure for the final training run shouldn't be your foundation for how much frontier AI models value. That is lower than 10% of the cost of Meta’s Llama." That’s a tiny fraction of the hundreds of hundreds of thousands to billions of dollars that US corporations like Google, Microsoft, xAI, and OpenAI have spent coaching their models. "If you’re a terrorist, you’d like to have an AI that’s very autonomous," he stated. Jordan Schneider: What’s interesting is you’ve seen an analogous dynamic where the established firms have struggled relative to the startups the place we had a Google was sitting on their palms for a while, and the identical factor with Baidu of simply not quite attending to where the unbiased labs have been. All bells and whistles aside, the deliverable that issues is how good the fashions are relative to FLOPs spent.
The post-coaching facet is much less revolutionary, however gives more credence to these optimizing for online RL coaching as DeepSeek did this (with a type of Constitutional AI, as pioneered by Anthropic)4. The $5M figure for the final training run shouldn't be your foundation for how much frontier AI models value. That is lower than 10% of the cost of Meta’s Llama." That’s a tiny fraction of the hundreds of hundreds of thousands to billions of dollars that US corporations like Google, Microsoft, xAI, and OpenAI have spent coaching their models. "If you’re a terrorist, you’d like to have an AI that’s very autonomous," he stated. Jordan Schneider: What’s interesting is you’ve seen an analogous dynamic where the established firms have struggled relative to the startups the place we had a Google was sitting on their palms for a while, and the identical factor with Baidu of simply not quite attending to where the unbiased labs have been. All bells and whistles aside, the deliverable that issues is how good the fashions are relative to FLOPs spent.
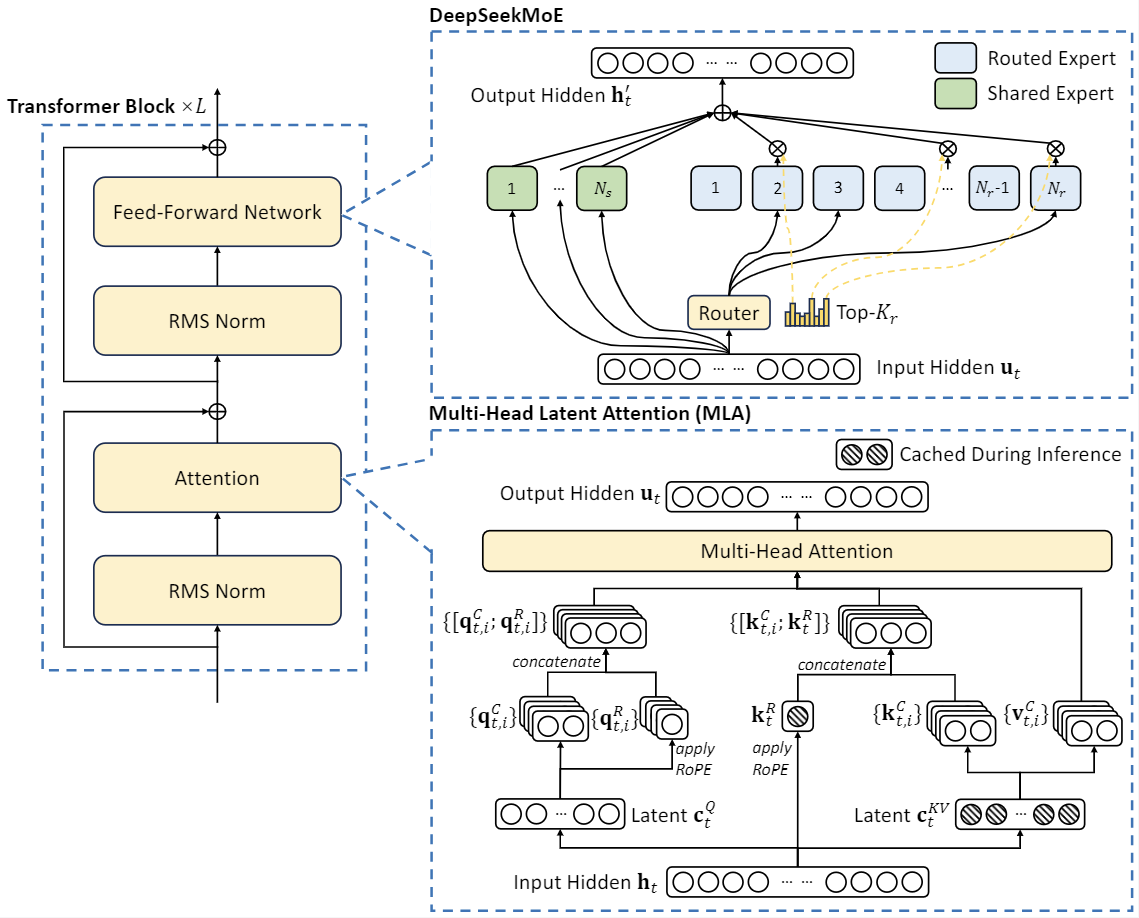 Llama three 405B used 30.8M GPU hours for training relative to DeepSeek V3’s 2.6M GPU hours (extra info in the Llama 3 mannequin card). In the course of the pre-coaching state, training DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our own cluster with 2048 H800 GPUs. For Chinese firms that are feeling the stress of substantial chip export controls, it can't be seen as notably surprising to have the angle be "Wow we will do method more than you with less." I’d most likely do the identical in their footwear, it's far more motivating than "my cluster is greater than yours." This goes to say that we'd like to grasp how essential the narrative of compute numbers is to their reporting. One necessary step towards that is displaying that we will study to characterize sophisticated games and then convey them to life from a neural substrate, which is what the authors have achieved right here.
Llama three 405B used 30.8M GPU hours for training relative to DeepSeek V3’s 2.6M GPU hours (extra info in the Llama 3 mannequin card). In the course of the pre-coaching state, training DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our own cluster with 2048 H800 GPUs. For Chinese firms that are feeling the stress of substantial chip export controls, it can't be seen as notably surprising to have the angle be "Wow we will do method more than you with less." I’d most likely do the identical in their footwear, it's far more motivating than "my cluster is greater than yours." This goes to say that we'd like to grasp how essential the narrative of compute numbers is to their reporting. One necessary step towards that is displaying that we will study to characterize sophisticated games and then convey them to life from a neural substrate, which is what the authors have achieved right here.
They recognized 25 sorts of verifiable directions and constructed round 500 prompts, with each immediate containing a number of verifiable directions. Yet fantastic tuning has too high entry level compared to simple API access and immediate engineering. The promise and edge of LLMs is the pre-trained state - no need to collect and label information, spend time and money coaching personal specialised fashions - simply immediate the LLM. Some of the noteworthy improvements in DeepSeek’s coaching stack embody the following. deepseek ai applied many tricks to optimize their stack that has solely been finished nicely at 3-5 other AI laboratories on the planet. deepseek ai china simply confirmed the world that none of that is definitely mandatory - that the "AI Boom" which has helped spur on the American economy in latest months, and which has made GPU companies like Nvidia exponentially more wealthy than they had been in October 2023, could also be nothing greater than a sham - and the nuclear energy "renaissance" along with it. We’ve already seen the rumblings of a response from American companies, as well as the White House. Since launch, we’ve also gotten affirmation of the ChatBotArena rating that locations them in the highest 10 and over the likes of latest Gemini professional models, Grok 2, o1-mini, etc. With solely 37B active parameters, that is extraordinarily interesting for a lot of enterprise functions.
Far from exhibiting itself to human academic endeavour as a scientific object, AI is a meta-scientific control system and an invader, with all of the insidiousness of planetary technocapital flipping over. 4. Model-based mostly reward models were made by starting with a SFT checkpoint of V3, then finetuning on human choice information containing each closing reward and chain-of-thought resulting in the final reward. × worth. The corresponding fees will be instantly deducted out of your topped-up balance or granted balance, with a choice for utilizing the granted balance first when both balances are available. AI race and whether or not the demand for AI chips will maintain. We will invoice primarily based on the entire variety of enter and output tokens by the mannequin. I hope that further distillation will occur and we are going to get nice and succesful models, good instruction follower in vary 1-8B. Thus far fashions below 8B are manner too fundamental in comparison with bigger ones. Luxonis." Models must get not less than 30 FPS on the OAK4. Closed models get smaller, i.e. get closer to their open-source counterparts.
If you beloved this post and you would like to obtain much more details about ديب سيك kindly pay a visit to our own web site.
- 이전글Turn Your Deepseek Into a High Performing Machine 25.02.01
- 다음글Are you experiencing issues with your car's engine control module (ECM) or powertrain control module (PCM)? 25.02.01
댓글목록
등록된 댓글이 없습니다.