What Are you able to Do About Deepseek Right Now
페이지 정보

본문
 Alternatively, you may obtain the DeepSeek app for iOS or Android, and use the chatbot on your smartphone. Using DeepSeek-V2 Base/Chat models is subject to the Model License. DeepSeek was the first firm to publicly match OpenAI, which earlier this 12 months launched the o1 class of fashions which use the identical RL method - an additional sign of how subtle DeepSeek is. The corporate prices its products and services nicely below market worth - and provides others away free deepseek of charge. The high-quality-tuning job relied on a rare dataset he’d painstakingly gathered over months - a compilation of interviews psychiatrists had finished with patients with psychosis, as well as interviews those self same psychiatrists had executed with AI techniques. I get pleasure from providing fashions and serving to individuals, and ديب سيك would love to have the ability to spend much more time doing it, in addition to increasing into new initiatives like superb tuning/coaching. Why this issues - signs of success: Stuff like Fire-Flyer 2 is a symptom of a startup that has been constructing refined infrastructure and coaching models for a few years. When the last human driver finally retires, we will replace the infrastructure for machines with cognition at kilobits/s. Read more: Sapiens: Foundation for Human Vision Models (arXiv).
Alternatively, you may obtain the DeepSeek app for iOS or Android, and use the chatbot on your smartphone. Using DeepSeek-V2 Base/Chat models is subject to the Model License. DeepSeek was the first firm to publicly match OpenAI, which earlier this 12 months launched the o1 class of fashions which use the identical RL method - an additional sign of how subtle DeepSeek is. The corporate prices its products and services nicely below market worth - and provides others away free deepseek of charge. The high-quality-tuning job relied on a rare dataset he’d painstakingly gathered over months - a compilation of interviews psychiatrists had finished with patients with psychosis, as well as interviews those self same psychiatrists had executed with AI techniques. I get pleasure from providing fashions and serving to individuals, and ديب سيك would love to have the ability to spend much more time doing it, in addition to increasing into new initiatives like superb tuning/coaching. Why this issues - signs of success: Stuff like Fire-Flyer 2 is a symptom of a startup that has been constructing refined infrastructure and coaching models for a few years. When the last human driver finally retires, we will replace the infrastructure for machines with cognition at kilobits/s. Read more: Sapiens: Foundation for Human Vision Models (arXiv).

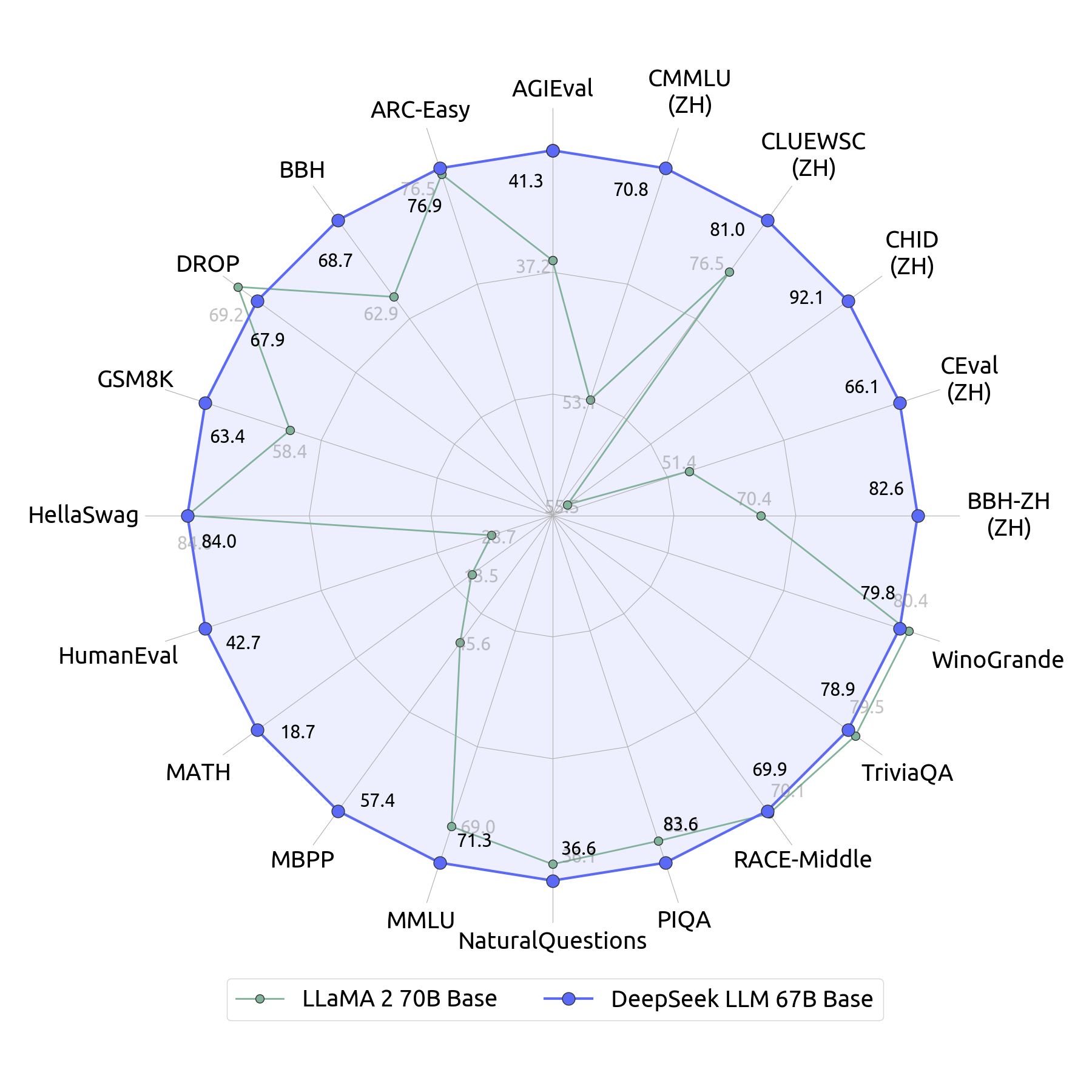
We’re thrilled to share our progress with the group and see the gap between open and closed models narrowing. "We estimate that compared to the very best worldwide requirements, even the very best home efforts face a few twofold hole in terms of model structure and coaching dynamics," Wenfeng says. Additionally, there’s a few twofold hole in knowledge efficiency, meaning we'd like twice the training data and computing energy to achieve comparable outcomes. Combined, this requires four occasions the computing energy. "This means we'd like twice the computing power to achieve the identical results. "This run presents a loss curve and convergence fee that meets or exceeds centralized training," Nous writes. Track the NOUS run right here (Nous DisTro dashboard). Take a look at Andrew Critch’s publish here (Twitter). There’s no simple answer to any of this - everyone (myself included) wants to determine their own morality and method here. John Muir, the Californian naturist, was mentioned to have let out a gasp when he first noticed the Yosemite valley, seeing unprecedentedly dense and love-stuffed life in its stone and timber and wildlife. K), a decrease sequence size might have to be used. "The practical data we have accrued may prove beneficial for each industrial and tutorial sectors.
Researchers at Tsinghua University have simulated a hospital, filled it with LLM-powered brokers pretending to be patients and medical employees, then proven that such a simulation can be used to enhance the true-world performance of LLMs on medical test exams… DeepSeek's first-generation of reasoning models with comparable performance to OpenAI-o1, including six dense fashions distilled from DeepSeek-R1 based on Llama and Qwen. AI CEO, Elon Musk, simply went online and started trolling DeepSeek’s performance claims. DeepSeek’s system: The system is known as Fire-Flyer 2 and is a hardware and software program system for doing massive-scale AI coaching. As DeepSeek’s founder said, the only challenge remaining is compute. If we get it incorrect, we’re going to be dealing with inequality on steroids - a small caste of individuals might be getting an enormous amount carried out, aided by ghostly superintelligences that work on their behalf, whereas a larger set of people watch the success of others and ask ‘why not me? The success of the corporate's A.I.
- 이전글Five Killer Quora Answers To Best Ovens Uk 25.02.01
- 다음글10 Things That Your Family Teach You About Ethanol Fireplaces 25.02.01
댓글목록
등록된 댓글이 없습니다.