What's New About Deepseek
페이지 정보

본문
The mannequin, deepseek ai V3, was developed by the AI firm DeepSeek and was released on Wednesday below a permissive license that enables builders to obtain and modify it for many applications, together with commercial ones. This resulted in DeepSeek-V2-Chat (SFT) which was not launched. We additional conduct supervised high-quality-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. The pipeline incorporates two RL phases aimed toward discovering improved reasoning patterns and aligning with human preferences, in addition to two SFT stages that serve as the seed for the mannequin's reasoning and non-reasoning capabilities. Non-reasoning data was generated by DeepSeek-V2.5 and checked by people. Using the reasoning data generated by DeepSeek-R1, we high-quality-tuned several dense models which can be widely used in the research community. Reasoning information was generated by "professional models". Reinforcement Learning (RL) Model: Designed to carry out math reasoning with suggestions mechanisms. Because it performs better than Coder v1 && LLM v1 at NLP / Math benchmarks.
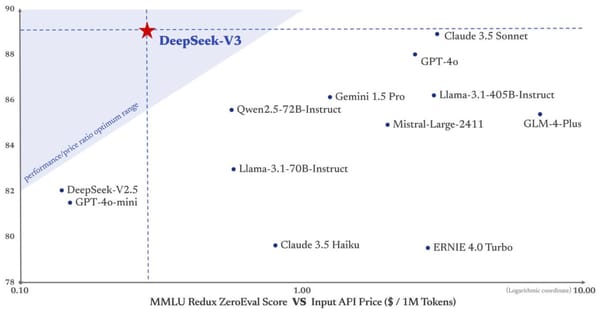 We display that the reasoning patterns of larger fashions may be distilled into smaller models, leading to better efficiency compared to the reasoning patterns discovered by means of RL on small fashions. The analysis results exhibit that the distilled smaller dense models carry out exceptionally nicely on benchmarks. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini throughout various benchmarks, achieving new state-of-the-artwork results for dense models. Despite being the smallest mannequin with a capability of 1.Three billion parameters, DeepSeek-Coder outperforms its bigger counterparts, StarCoder and CodeLlama, in these benchmarks. "The model itself gives away a number of particulars of how it works, but the costs of the primary adjustments that they claim - that I understand - don’t ‘show up’ in the mannequin itself a lot," Miller advised Al Jazeera. "the model is prompted to alternately describe an answer step in pure language after which execute that step with code". "GPT-4 completed training late 2022. There have been a variety of algorithmic and hardware enhancements since 2022, driving down the cost of training a GPT-4 class model. If your system doesn't have quite enough RAM to fully load the model at startup, you may create a swap file to help with the loading.
We display that the reasoning patterns of larger fashions may be distilled into smaller models, leading to better efficiency compared to the reasoning patterns discovered by means of RL on small fashions. The analysis results exhibit that the distilled smaller dense models carry out exceptionally nicely on benchmarks. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini throughout various benchmarks, achieving new state-of-the-artwork results for dense models. Despite being the smallest mannequin with a capability of 1.Three billion parameters, DeepSeek-Coder outperforms its bigger counterparts, StarCoder and CodeLlama, in these benchmarks. "The model itself gives away a number of particulars of how it works, but the costs of the primary adjustments that they claim - that I understand - don’t ‘show up’ in the mannequin itself a lot," Miller advised Al Jazeera. "the model is prompted to alternately describe an answer step in pure language after which execute that step with code". "GPT-4 completed training late 2022. There have been a variety of algorithmic and hardware enhancements since 2022, driving down the cost of training a GPT-4 class model. If your system doesn't have quite enough RAM to fully load the model at startup, you may create a swap file to help with the loading.
This produced the Instruct model. This produced an internal mannequin not released. On 9 January 2024, they launched 2 DeepSeek-MoE models (Base, Chat), every of 16B parameters (2.7B activated per token, 4K context length). Multiple quantisation parameters are provided, to allow you to choose the best one in your hardware and necessities. For recommendations on the perfect pc hardware configurations to handle Deepseek models smoothly, take a look at this information: Best Computer for Running LLaMA and LLama-2 Models. The AI community will be digging into them and we’ll discover out," Pedro Domingos, professor emeritus of computer science and engineering on the University of Washington, told Al Jazeera. Tim Miller, a professor specialising in AI at the University of Queensland, said it was troublesome to say how much inventory must be put in DeepSeek’s claims. After inflicting shockwaves with an AI model with capabilities rivalling the creations of Google and OpenAI, China’s DeepSeek is dealing with questions about whether its daring claims stand as much as scrutiny.
5 Like deepseek ai china Coder, the code for the mannequin was underneath MIT license, with DeepSeek license for the model itself. I’d guess the latter, since code environments aren’t that simple to setup. We offer varied sizes of the code mannequin, starting from 1B to 33B variations. Roose, Kevin (28 January 2025). "Why DeepSeek Could Change What Silicon Valley Believe A couple of.I." The brand new York Times. Goldman, David (27 January 2025). "What's DeepSeek, the Chinese AI startup that shook the tech world? | CNN Business". Cosgrove, Emma (27 January 2025). "DeepSeek's cheaper models and weaker chips call into question trillions in AI infrastructure spending". Dou, Eva; Gregg, Aaron; Zakrzewski, Cat; Tiku, Nitasha; Najmabadi, Shannon (28 January 2025). "Trump calls China's DeepSeek AI app a 'wake-up call' after tech stocks slide". Booth, Robert; Milmo, Dan (28 January 2025). "Experts urge caution over use of Chinese AI DeepSeek". Unlike many American AI entrepreneurs who are from Silicon Valley, Mr Liang also has a background in finance. Various publications and news media, such as the Hill and The Guardian, described the discharge of its chatbot as a "Sputnik moment" for American A.I.
- 이전글9 Lessons Your Parents Teach You About Bifold Door Repair 25.02.01
- 다음글The Important Thing To Successful Deepseek 25.02.01
댓글목록
등록된 댓글이 없습니다.