Nine Small Changes That Will have A Huge Impact In Your Deepseek
페이지 정보

본문
 If DeepSeek V3, or a similar model, was launched with full coaching information and code, as a real open-supply language model, then the associated fee numbers can be true on their face value. While DeepSeek-V3, on account of its structure being Mixture-of-Experts, and educated with a considerably higher amount of data, beats even closed-supply variations on some particular benchmarks in maths, code, and Chinese languages, it falters significantly behind in different places, as an example, its poor efficiency with factual data for English. Phi-four is suitable for STEM use instances, Llama 3.3 for multilingual dialogue and lengthy-context purposes, and DeepSeek-V3 for math, code, and Chinese performance, although it's weak in English factual information. In addition, DeepSeek-V3 additionally employs information distillation approach that permits the transfer of reasoning capability from the DeepSeek-R1 collection. This selective activation reduces the computational prices considerably bringing out the power to perform nicely whereas frugal with computation. However, the report says finishing up actual-world attacks autonomously is past AI techniques to date as a result of they require "an exceptional stage of precision". The potential for synthetic intelligence techniques for use for malicious acts is growing, in response to a landmark report by AI experts, with the study’s lead writer warning that DeepSeek and other disruptors could heighten the safety risk.
If DeepSeek V3, or a similar model, was launched with full coaching information and code, as a real open-supply language model, then the associated fee numbers can be true on their face value. While DeepSeek-V3, on account of its structure being Mixture-of-Experts, and educated with a considerably higher amount of data, beats even closed-supply variations on some particular benchmarks in maths, code, and Chinese languages, it falters significantly behind in different places, as an example, its poor efficiency with factual data for English. Phi-four is suitable for STEM use instances, Llama 3.3 for multilingual dialogue and lengthy-context purposes, and DeepSeek-V3 for math, code, and Chinese performance, although it's weak in English factual information. In addition, DeepSeek-V3 additionally employs information distillation approach that permits the transfer of reasoning capability from the DeepSeek-R1 collection. This selective activation reduces the computational prices considerably bringing out the power to perform nicely whereas frugal with computation. However, the report says finishing up actual-world attacks autonomously is past AI techniques to date as a result of they require "an exceptional stage of precision". The potential for synthetic intelligence techniques for use for malicious acts is growing, in response to a landmark report by AI experts, with the study’s lead writer warning that DeepSeek and other disruptors could heighten the safety risk.
To report a potential bug, please open a problem. Future work will concern further design optimization of architectures for enhanced coaching and inference efficiency, potential abandonment of the Transformer structure, and excellent context size of infinite. The joint work of Tsinghua University and Zhipu AI, CodeGeeX4 has fixed these issues and made gigantic enhancements, because of suggestions from the AI analysis neighborhood. For specialists in AI, its MoE structure and training schemes are the idea for research and a practical LLM implementation. Its large really helpful deployment measurement may be problematic for lean groups as there are simply too many features to configure. For the general public, DeepSeek-V3 suggests superior and adaptive AI tools in everyday utilization together with a greater search, translate, and virtual assistant features enhancing circulation of information and simplifying on a regular basis tasks. By implementing these methods, DeepSeekMoE enhances the efficiency of the model, permitting it to perform higher than other MoE models, particularly when handling bigger datasets.
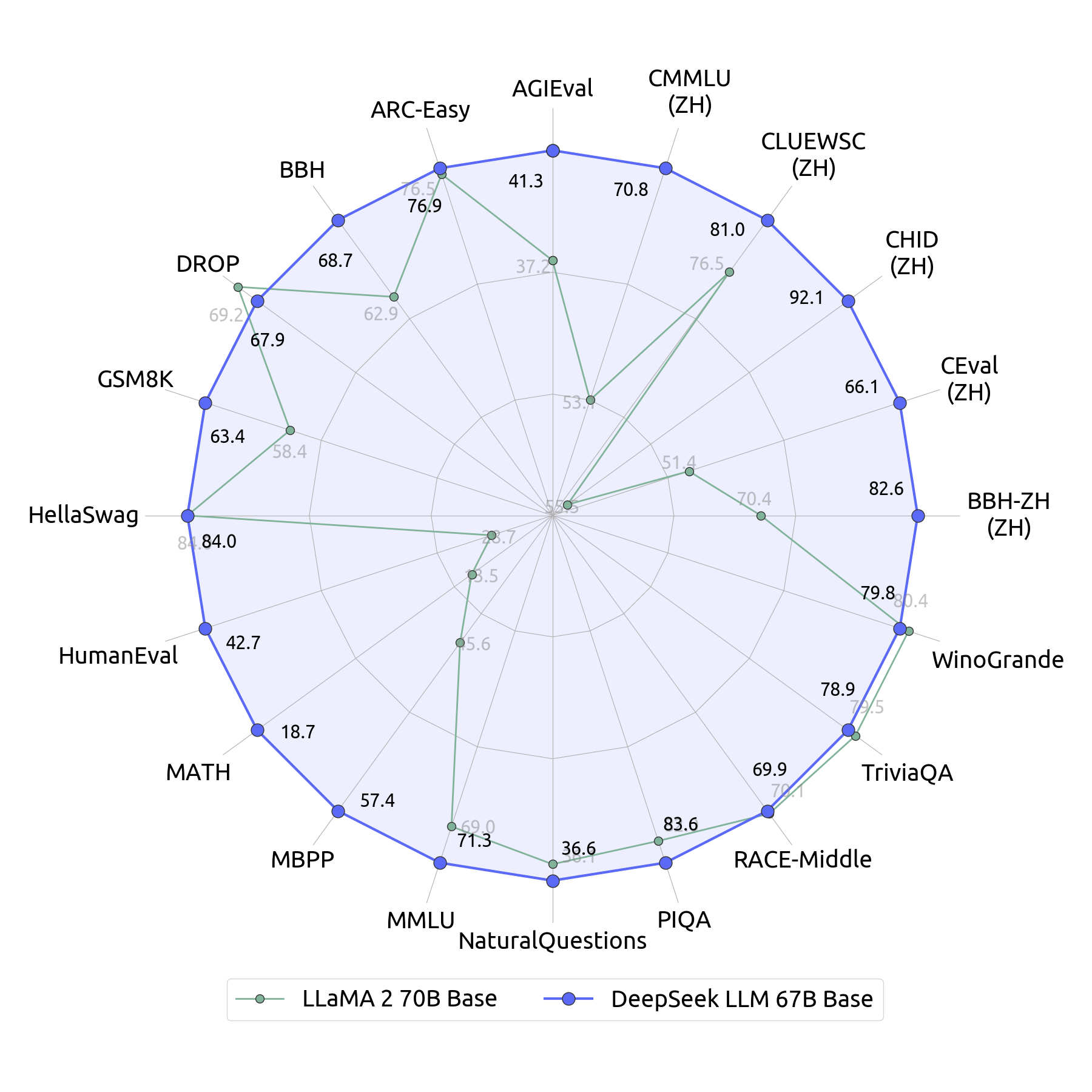
Based on the strict comparison with different highly effective language fashions, DeepSeek-V3’s great efficiency has been proven convincingly. DeepSeek-V3, Phi-4, and Llama 3.3 have strengths compared as large language models. Though it really works properly in a number of language duties, it would not have the targeted strengths of Phi-four on STEM or DeepSeek-V3 on Chinese. Phi-4 is educated on a mixture of synthesized and natural knowledge, focusing extra on reasoning, and provides outstanding efficiency in STEM Q&A and coding, generally even giving extra correct results than its teacher mannequin GPT-4o. Despite being worse at coding, they state that DeepSeek-Coder-v1.5 is healthier. This architecture can make it obtain high efficiency with higher effectivity and extensibility. These models can do every part from code snippet technology to translation of whole capabilities and code translation throughout languages. This focused method results in more practical era of code because the defects are focused and thus coded in contrast to normal function models where the defects could be haphazard. Different benchmarks encompassing each English and crucial Chinese language duties are used to check DeepSeek-V3 to open-source competitors such as Qwen2.5 and LLaMA-3.1 and closed-supply competitors equivalent to GPT-4o and Claude-3.5-Sonnet.
Analyzing the outcomes, it turns into apparent that DeepSeek-V3 is also among the most effective variant most of the time being on par with and generally outperforming the other open-supply counterparts while almost at all times being on par with or higher than the closed-source benchmarks. So simply because a person is prepared to pay higher premiums, doesn’t mean they deserve higher care. There might be payments to pay and right now it would not appear to be it's going to be corporations. So yeah, there’s too much coming up there. I'd say that’s plenty of it. Earlier last yr, many would have thought that scaling and GPT-5 class fashions would function in a price that DeepSeek cannot afford. It makes use of much less memory than its rivals, finally reducing the fee to perform duties. DeepSeek mentioned one among its fashions cost $5.6 million to practice, a fraction of the cash usually spent on related projects in Silicon Valley. The use of a Mixture-of-Experts (MoE AI models) has come out as one of the best solutions to this problem. MoE fashions split one mannequin into a number of specific, smaller sub-networks, referred to as ‘experts’ the place the model can drastically improve its capability without experiencing destructive escalations in computational expense.
If you adored this article and you also would like to be given more info concerning ديب سيك nicely visit our own internet site.
- 이전글Discover the Best Slot Gacor Sites for Big Wins 25.02.01
- 다음글تفسير المراغي/سورة الأنعام 25.02.01
댓글목록
등록된 댓글이 없습니다.