The Meaning Of Deepseek
페이지 정보

본문
5 Like DeepSeek Coder, the code for the mannequin was below MIT license, with DeepSeek license for the model itself. DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is initially licensed beneath llama3.Three license. GRPO helps the mannequin develop stronger mathematical reasoning abilities whereas additionally improving its reminiscence utilization, making it more efficient. There are tons of fine options that helps in reducing bugs, decreasing overall fatigue in constructing good code. I’m not really clued into this part of the LLM world, however it’s good to see Apple is putting in the work and the community are doing the work to get these running nice on Macs. The H800 playing cards inside a cluster are connected by NVLink, and the clusters are related by InfiniBand. They minimized the communication latency by overlapping extensively computation and communication, comparable to dedicating 20 streaming multiprocessors out of 132 per H800 for only inter-GPU communication. Imagine, I've to shortly generate a OpenAPI spec, as we speak I can do it with one of many Local LLMs like Llama utilizing Ollama.
It was developed to compete with different LLMs obtainable on the time. Venture capital firms have been reluctant in providing funding because it was unlikely that it would be able to generate an exit in a short period of time. To support a broader and more various range of research inside each academic and commercial communities, we're offering access to the intermediate checkpoints of the bottom mannequin from its training course of. The paper's experiments show that existing strategies, comparable to simply offering documentation, are not adequate for enabling LLMs to incorporate these modifications for downside solving. They proposed the shared consultants to learn core capacities that are often used, and let the routed experts to study the peripheral capacities that are hardly ever used. In structure, it's a variant of the usual sparsely-gated MoE, with "shared specialists" that are always queried, and "routed experts" that might not be. Using the reasoning information generated by DeepSeek-R1, we fantastic-tuned several dense models which are broadly used in the research community.
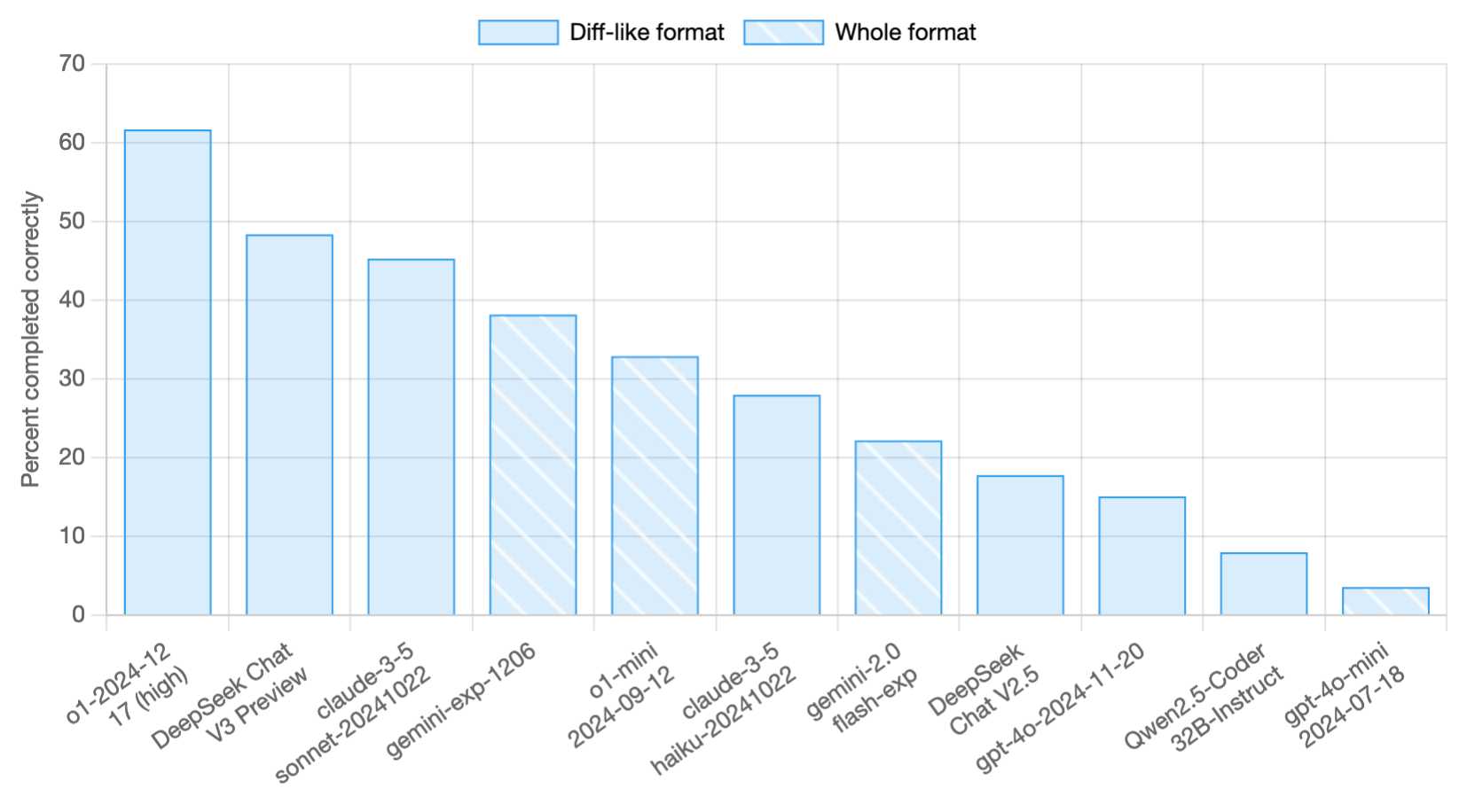 Expert fashions have been used, as a substitute of R1 itself, because the output from R1 itself suffered "overthinking, poor formatting, and extreme length". Both had vocabulary measurement 102,four hundred (byte-stage BPE) and context length of 4096. They educated on 2 trillion tokens of English and Chinese text obtained by deduplicating the Common Crawl. 2. Extend context length from 4K to 128K utilizing YaRN. 2. Extend context size twice, from 4K to 32K and then to 128K, using YaRN. On 9 January 2024, they launched 2 DeepSeek-MoE fashions (Base, Chat), each of 16B parameters (2.7B activated per token, 4K context size). In December 2024, they released a base model DeepSeek-V3-Base and a chat mannequin DeepSeek-V3. With a view to foster research, now we have made DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open supply for the analysis community. The Chat variations of the 2 Base fashions was also released concurrently, obtained by coaching Base by supervised finetuning (SFT) adopted by direct coverage optimization (DPO). DeepSeek-V2.5 was released in September and up to date in December 2024. It was made by combining deepseek ai china-V2-Chat and DeepSeek-Coder-V2-Instruct.
Expert fashions have been used, as a substitute of R1 itself, because the output from R1 itself suffered "overthinking, poor formatting, and extreme length". Both had vocabulary measurement 102,four hundred (byte-stage BPE) and context length of 4096. They educated on 2 trillion tokens of English and Chinese text obtained by deduplicating the Common Crawl. 2. Extend context length from 4K to 128K utilizing YaRN. 2. Extend context size twice, from 4K to 32K and then to 128K, using YaRN. On 9 January 2024, they launched 2 DeepSeek-MoE fashions (Base, Chat), each of 16B parameters (2.7B activated per token, 4K context size). In December 2024, they released a base model DeepSeek-V3-Base and a chat mannequin DeepSeek-V3. With a view to foster research, now we have made DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open supply for the analysis community. The Chat variations of the 2 Base fashions was also released concurrently, obtained by coaching Base by supervised finetuning (SFT) adopted by direct coverage optimization (DPO). DeepSeek-V2.5 was released in September and up to date in December 2024. It was made by combining deepseek ai china-V2-Chat and DeepSeek-Coder-V2-Instruct.
This resulted in DeepSeek-V2-Chat (SFT) which was not released. All skilled reward fashions had been initialized from DeepSeek-V2-Chat (SFT). 4. Model-based reward models had been made by beginning with a SFT checkpoint of V3, then finetuning on human desire information containing each final reward and chain-of-thought leading to the ultimate reward. The rule-based mostly reward was computed for math problems with a remaining reply (put in a box), and for programming problems by unit assessments. Benchmark tests show that DeepSeek-V3 outperformed Llama 3.1 and Qwen 2.5 while matching GPT-4o and Claude 3.5 Sonnet. DeepSeek-R1-Distill models can be utilized in the same method as Qwen or Llama models. Smaller open models have been catching up throughout a variety of evals. I’ll go over every of them with you and given you the pros and cons of every, then I’ll show you ways I arrange all three of them in my Open WebUI instance! Even when the docs say All the frameworks we suggest are open source with energetic communities for support, and might be deployed to your own server or a internet hosting supplier , it fails to mention that the hosting or server requires nodejs to be working for this to work. Some sources have noticed that the official utility programming interface (API) version of R1, which runs from servers positioned in China, uses censorship mechanisms for topics that are thought-about politically sensitive for the government of China.
When you loved this short article as well as you want to receive more info with regards to Deep Seek generously visit our website.
- 이전글7 Helpful Tricks To Making The Most Out Of Your Bio Ethanol Fireplace 25.02.01
- 다음글Is It Time To speak Extra ABout Deepseek? 25.02.01
댓글목록
등록된 댓글이 없습니다.