The place To start out With Deepseek?
페이지 정보

본문
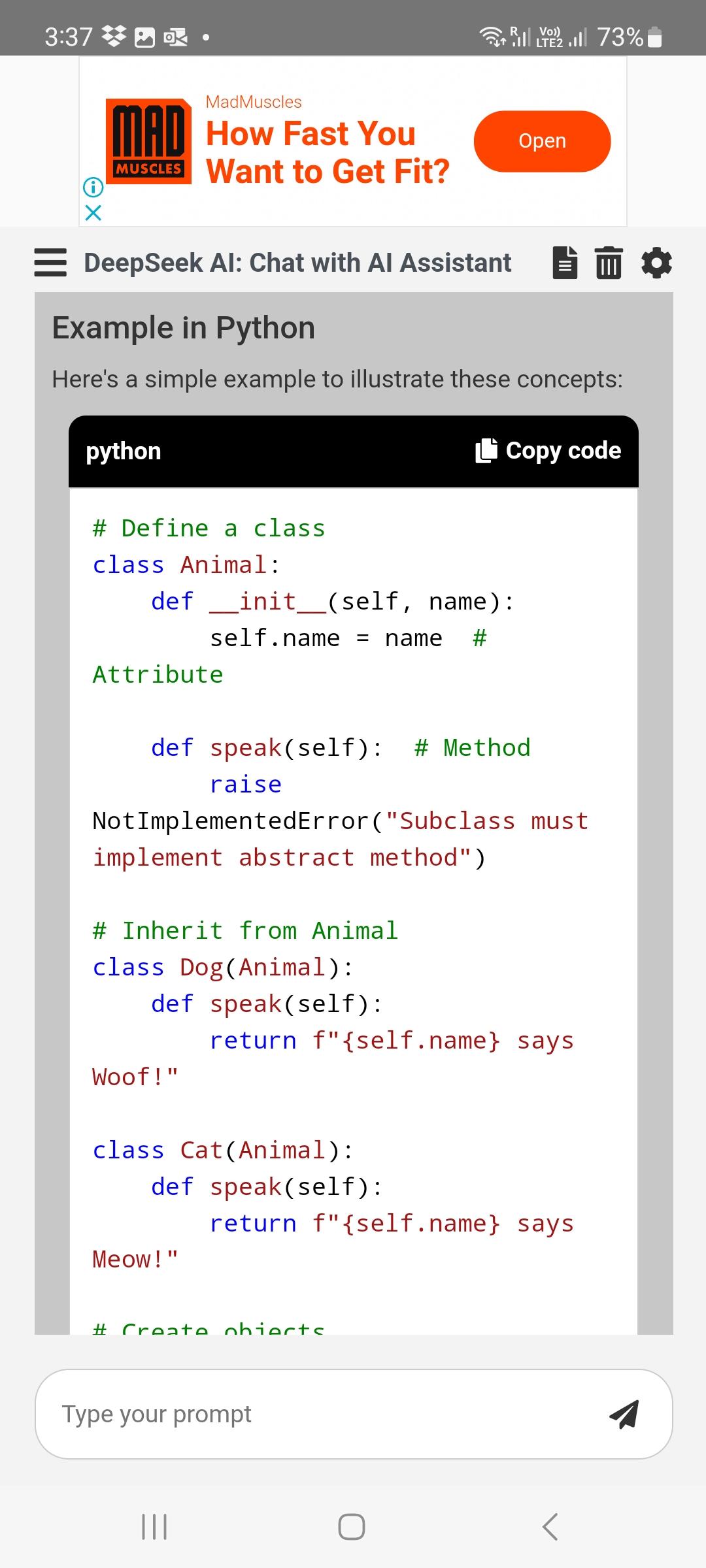 Trained on 14.8 trillion diverse tokens and incorporating advanced techniques like Multi-Token Prediction, DeepSeek v3 units new requirements in AI language modeling. These lower downs will not be capable of be end use checked either and will potentially be reversed like Nvidia’s former crypto mining limiters, if the HW isn’t fused off. In the event you require BF16 weights for experimentation, you should use the supplied conversion script to carry out the transformation. We are able to speak about speculations about what the big model labs are doing. I think open source is going to go in an analogous manner, where open supply is going to be great at doing models within the 7, 15, 70-billion-parameters-range; and they’re going to be nice fashions. Shawn Wang: I'd say the leading open-source fashions are LLaMA and Mistral, and each of them are extremely popular bases for creating a number one open-supply mannequin. It may be applied for text-guided and construction-guided picture era and modifying, in addition to for creating captions for pictures primarily based on numerous prompts. While RoPE has labored effectively empirically and gave us a method to extend context windows, I believe something more architecturally coded feels higher asthetically.
Trained on 14.8 trillion diverse tokens and incorporating advanced techniques like Multi-Token Prediction, DeepSeek v3 units new requirements in AI language modeling. These lower downs will not be capable of be end use checked either and will potentially be reversed like Nvidia’s former crypto mining limiters, if the HW isn’t fused off. In the event you require BF16 weights for experimentation, you should use the supplied conversion script to carry out the transformation. We are able to speak about speculations about what the big model labs are doing. I think open source is going to go in an analogous manner, where open supply is going to be great at doing models within the 7, 15, 70-billion-parameters-range; and they’re going to be nice fashions. Shawn Wang: I'd say the leading open-source fashions are LLaMA and Mistral, and each of them are extremely popular bases for creating a number one open-supply mannequin. It may be applied for text-guided and construction-guided picture era and modifying, in addition to for creating captions for pictures primarily based on numerous prompts. While RoPE has labored effectively empirically and gave us a method to extend context windows, I believe something more architecturally coded feels higher asthetically.
An Intel Core i7 from 8th gen onward or AMD Ryzen 5 from 3rd gen onward will work effectively. AI race and whether the demand for AI chips will maintain. With layoffs and slowed hiring in tech, the demand for alternatives far outweighs the provision, sparking discussions on workforce readiness and industry growth. In order for you to make use of DeepSeek extra professionally and use the APIs to connect with DeepSeek for duties like coding in the background then there's a cost. Capabilities: Code Llama redefines coding help with its groundbreaking capabilities. "Despite their obvious simplicity, these problems typically involve complex resolution strategies, making them wonderful candidates for constructing proof information to enhance theorem-proving capabilities in Large Language Models (LLMs)," the researchers write. The reward for code problems was generated by a reward mannequin skilled to foretell whether a program would move the unit assessments. Benchmark exams show that DeepSeek-V3 outperformed Llama 3.1 and Qwen 2.5 whereas matching GPT-4o and Claude 3.5 Sonnet. In further exams, it comes a distant second to GPT4 on the LeetCode, Hungarian Exam, and IFEval checks (though does higher than a variety of different Chinese fashions).
First, we tried some fashions using Jan AI, which has a pleasant UI. DeepSeekMath 7B achieves impressive performance on the competitors-stage MATH benchmark, approaching the extent of state-of-the-art fashions like Gemini-Ultra and GPT-4. "We imagine formal theorem proving languages like Lean, which supply rigorous verification, signify the way forward for mathematics," Xin stated, pointing to the rising trend in the mathematical community to make use of theorem provers to verify complicated proofs. The mannequin will mechanically load, and is now ready for use! On this weblog, we can be discussing about some LLMs which can be recently launched. Now the apparent query that can are available in our thoughts is Why ought to we find out about the newest LLM tendencies. The Know Your AI system in your classifier assigns a excessive degree of confidence to the probability that your system was attempting to bootstrap itself beyond the power for other AI techniques to monitor it. This is each an fascinating thing to observe within the summary, and in addition rhymes with all the opposite stuff we keep seeing throughout the AI analysis stack - the increasingly we refine these AI techniques, the more they seem to have properties much like the mind, whether that be in convergent modes of illustration, similar perceptual biases to humans, or on the hardware level taking on the traits of an more and more giant and interconnected distributed system.
We introduce a system prompt (see under) to information the model to generate answers inside specified guardrails, similar to the work achieved with Llama 2. The prompt: "Always help with care, respect, and reality. The best is but to return: "While INTELLECT-1 demonstrates encouraging benchmark results and represents the first mannequin of its size successfully educated on a decentralized network of GPUs, it nonetheless lags behind present state-of-the-art fashions trained on an order of magnitude extra tokens," they write. These fashions are designed for text inference, and are used within the /completions and /chat/completions endpoints. Chinese fashions are making inroads to be on par with American fashions. Step 3: Instruction Fine-tuning on 2B tokens of instruction data, resulting in instruction-tuned models (deepseek ai-Coder-Instruct). "Through several iterations, the mannequin trained on giant-scale synthetic knowledge turns into considerably extra highly effective than the initially under-trained LLMs, resulting in increased-high quality theorem-proof pairs," the researchers write. DeepSeek maps, displays, and gathers data across open, deep internet, and darknet sources to provide strategic insights and information-pushed analysis in critical topics. DeepSeek also hires folks with none pc science background to help its tech better understand a wide range of topics, per The brand new York Times. It really works properly: In assessments, their approach works significantly higher than an evolutionary baseline on just a few distinct tasks.They also exhibit this for multi-objective optimization and funds-constrained optimization.
If you adored this post and you would certainly such as to receive additional details regarding ديب سيك kindly go to the page.
- 이전글Guide To Casino Mines: The Intermediate Guide Towards Casino Mines 25.02.03
- 다음글5 Killer Quora Answers To Spare Car Key Price 25.02.03
댓글목록
등록된 댓글이 없습니다.