Notes on the Brand New Deepseek R1
페이지 정보

본문
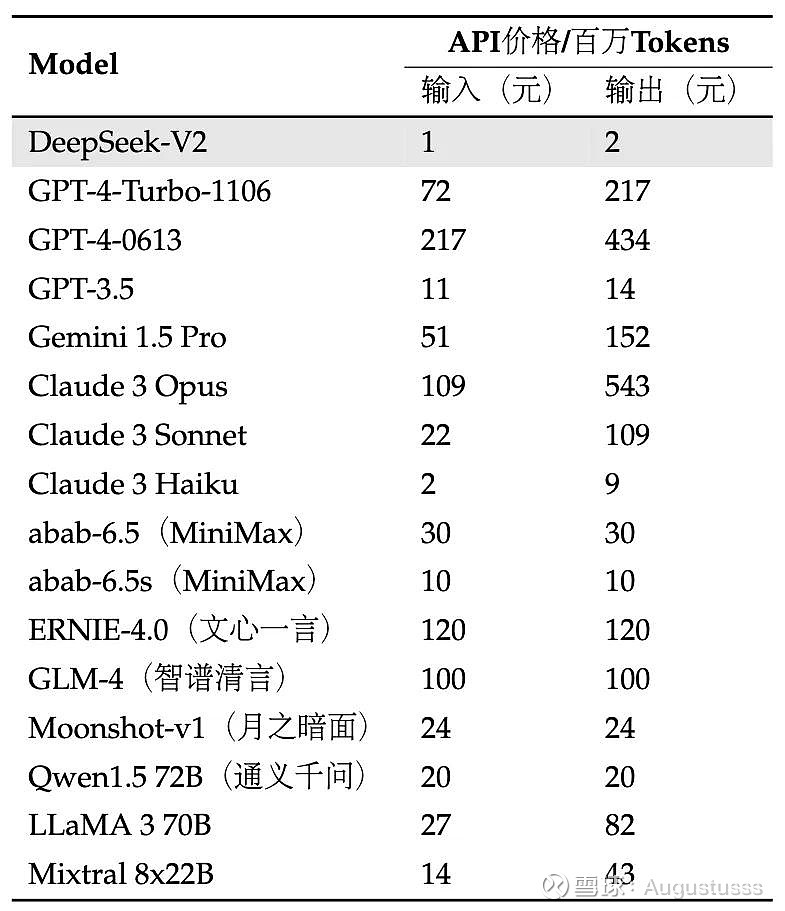 DeepSeek-V2 is a sophisticated Mixture-of-Experts (MoE) language mannequin developed by DeepSeek AI, a number one Chinese synthetic intelligence company. DeepSeek’s AI mannequin has sent shockwaves via the global tech business. But in contrast to a lot of these firms, all of DeepSeek’s fashions are open source, that means their weights and training methods are freely obtainable for the public to study, use and construct upon. DeepSeek’s progressive method transforms how organizations extract worth from data, enabling sooner and more accurate resolution-making. Improves determination-making by way of accurate knowledge interpretation. When it comes to performance, both models were put to the take a look at using historical monetary information of SPY investments. Actions that in any other case violate our site's phrases. Some, resembling Minimax and Moonshot, are giving up on pricey foundational model training to hone in on constructing client-going through functions on prime of others’ models. Its intuitive interface and pure language capabilities make it easy to make use of, even for those who usually are not tech-savvy. In addition to automated code-repairing with analytic tooling to indicate that even small fashions can perform nearly as good as huge models with the appropriate tools within the loop. DeepSeek revolutionizes legal analysis by rapidly figuring out related case legal guidelines, legal precedents, and rules, even inside vast authorized databases. Impact: Accelerated discovery fosters innovation, reduces the time spent on literature critiques, and enhances collaboration between analysis groups.
DeepSeek-V2 is a sophisticated Mixture-of-Experts (MoE) language mannequin developed by DeepSeek AI, a number one Chinese synthetic intelligence company. DeepSeek’s AI mannequin has sent shockwaves via the global tech business. But in contrast to a lot of these firms, all of DeepSeek’s fashions are open source, that means their weights and training methods are freely obtainable for the public to study, use and construct upon. DeepSeek’s progressive method transforms how organizations extract worth from data, enabling sooner and more accurate resolution-making. Improves determination-making by way of accurate knowledge interpretation. When it comes to performance, both models were put to the take a look at using historical monetary information of SPY investments. Actions that in any other case violate our site's phrases. Some, resembling Minimax and Moonshot, are giving up on pricey foundational model training to hone in on constructing client-going through functions on prime of others’ models. Its intuitive interface and pure language capabilities make it easy to make use of, even for those who usually are not tech-savvy. In addition to automated code-repairing with analytic tooling to indicate that even small fashions can perform nearly as good as huge models with the appropriate tools within the loop. DeepSeek revolutionizes legal analysis by rapidly figuring out related case legal guidelines, legal precedents, and rules, even inside vast authorized databases. Impact: Accelerated discovery fosters innovation, reduces the time spent on literature critiques, and enhances collaboration between analysis groups.
DeepSeek drastically reduces the time required to search out actionable info whereas delivering highly relevant and correct outcomes. Example: Instead of merely matching key phrases, DeepSeek interprets the user’s intent, providing results that align with the broader context of the question. These benchmark outcomes spotlight DeepSeek Coder V2's aggressive edge in each coding and mathematical reasoning duties. AGIEval: A human-centric benchmark for evaluating basis fashions. LLaMA: Open and environment friendly foundation language fashions. Yarn: Efficient context window extension of large language models. At the massive scale, we practice a baseline MoE model comprising roughly 230B total parameters on round 0.9T tokens. Specifically, block-clever quantization of activation gradients results in mannequin divergence on an MoE model comprising approximately 16B whole parameters, skilled for around 300B tokens. An identical process can also be required for the activation gradient. Although our tile-sensible nice-grained quantization successfully mitigates the error introduced by function outliers, it requires different groupings for activation quantization, i.e., 1x128 in forward go and 128x1 for backward pass. A simple technique is to use block-sensible quantization per 128x128 parts like the best way we quantize the model weights. Watch a demo video made by my colleague Du’An Lightfoot for importing the model and inference in the Bedrock playground.
Hybrid 8-bit floating level (HFP8) coaching and inference for deep neural networks. Fast inference from transformers through speculative decoding. These improvements end result from enhanced training methods, expanded datasets, and increased model scale, making Janus-Pro a state-of-the-art unified multimodal mannequin with strong generalization across tasks. Its structure handles huge datasets, making it a really perfect solution for small organizations and global enterprises managing terabytes of data. DeepSeek processes actual-time knowledge streams, financial reviews, and market trends to predict risks and uncover progress opportunities within the financial sector. From crowdsourced data to high-high quality benchmarks: Arena-onerous and benchbuilder pipeline. The one restriction (for now) is that the mannequin must already be pulled. U.S. AI firms aren't going to easily throw within the towel now that China has constructed a less expensive mousetrap -- especially when that mousetrap is open-supply. The expansion of Chinese-controlled digital companies has change into a major matter of concern for U.S. When the BBC requested the app what happened at Tiananmen Square on four June 1989, DeepSeek didn't give any particulars concerning the massacre, a taboo subject in China, which is topic to authorities censorship.
How DeepSeek was able to achieve its performance at its cost is the subject of ongoing discussion. Multilingual Capabilities: DeepSeek demonstrates exceptional efficiency in multilingual duties. They claimed efficiency comparable to a 16B MoE as a 7B non-MoE. Cmath: Can your language model pass chinese language elementary college math take a look at? DeepSeek is a Chinese artificial intelligence company specializing in the event of open-source giant language fashions (LLMs). For buyers, whereas DeepSeek AI is currently not listed on public inventory exchanges, it remains a extremely sought-after non-public firm in the AI house, backed by main venture capital companies. Right Sidebar Integration: The webview opens in the best sidebar by default for quick access while coding. ✅ Seamless Integration: Works straight in Chrome-no tabs, no apps. ✅ User-Centric Design: Built for simplicity. DeepSeek-R1 is an open-supply reasoning model that matches OpenAI-o1 in math, reasoning, and code duties. The model is accessible on the AI/ML API platform as "DeepSeek V3" . Advanced AI-powered search and analysis platform. Its features set it apart from conventional terminals, with its AI-powered instruments being probably the most notable ones.
If you cherished this article and you would like to acquire a lot more data with regards to ديب سيك kindly visit our web site.
- 이전글10 Startups That Are Set To Revolutionize The Emergency Car Key Replacement Industry For The Better 25.02.07
- 다음글20 Things Only The Most Devoted Ghost Immobilisers Fans Should Know 25.02.07
댓글목록
등록된 댓글이 없습니다.