Which Countries have Banned DeepSeek And Why?
페이지 정보

본문
DeepSeek site V3 also crushes the competition on Aider Polyglot, a take a look at designed to measure, among different issues, whether a mannequin can successfully write new code that integrates into current code. Proof Assistant Integration: The system seamlessly integrates with a proof assistant, which supplies feedback on the validity of the agent's proposed logical steps. 1. Data Generation: It generates pure language steps for inserting data into a PostgreSQL database primarily based on a given schema. The massive language model uses a mixture-of-specialists architecture with 671B parameters, of which solely 37B are activated for every process. Reinforcement Learning: The system uses reinforcement learning to discover ways to navigate the search space of possible logical steps. The first model, @hf/thebloke/deepseek-coder-6.7b-base-awq, generates pure language steps for knowledge insertion. The paper presents a new giant language mannequin referred to as DeepSeekMath 7B that is particularly designed to excel at mathematical reasoning. The researchers evaluate the performance of DeepSeekMath 7B on the competitors-level MATH benchmark, and the model achieves an impressive score of 51.7% without counting on external toolkits or voting techniques. Exploring the system's performance on extra difficult problems can be an important subsequent step. Dependence on Proof Assistant: The system's performance is heavily dependent on the capabilities of the proof assistant it's integrated with.
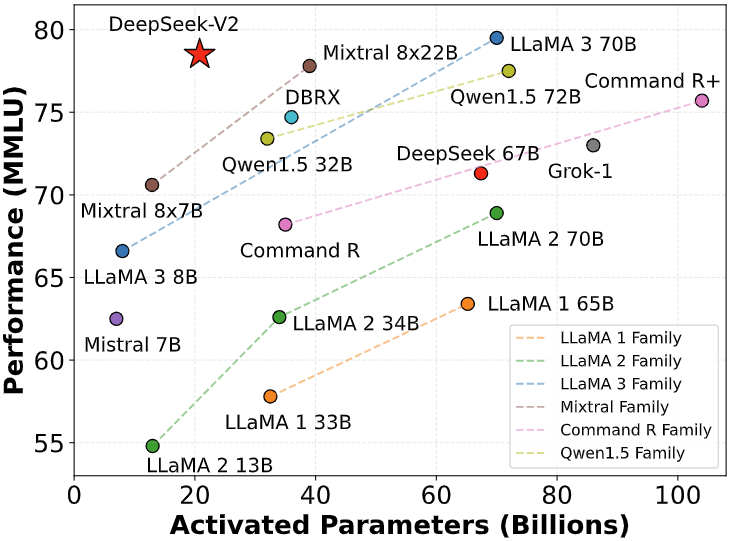 It is designed for real world AI software which balances velocity, price and performance. Cost: we comply with the formulation to derive the cost per one thousand perform callings. Task Automation: Automate repetitive tasks with its operate calling capabilities. Cate Hall: Someone is asking individuals from my number, saying they have kidnapped me and are going to kill me except the individual sends cash. Currently Llama three 8B is the biggest mannequin supported, and they've token generation limits much smaller than among the fashions accessible. China - i.e. how a lot is intentional policy vs. Through its AI Capacity-Building Action Plan for Good and for All, China has explicitly acknowledged its aim of sharing its greatest practices with the developing world, finishing up AI schooling and exchange packages, and constructing knowledge infrastructure to promote truthful and inclusive access to global knowledge. The purpose is to replace an LLM in order that it will possibly resolve these programming duties without being provided the documentation for the API changes at inference time.
It is designed for real world AI software which balances velocity, price and performance. Cost: we comply with the formulation to derive the cost per one thousand perform callings. Task Automation: Automate repetitive tasks with its operate calling capabilities. Cate Hall: Someone is asking individuals from my number, saying they have kidnapped me and are going to kill me except the individual sends cash. Currently Llama three 8B is the biggest mannequin supported, and they've token generation limits much smaller than among the fashions accessible. China - i.e. how a lot is intentional policy vs. Through its AI Capacity-Building Action Plan for Good and for All, China has explicitly acknowledged its aim of sharing its greatest practices with the developing world, finishing up AI schooling and exchange packages, and constructing knowledge infrastructure to promote truthful and inclusive access to global knowledge. The purpose is to replace an LLM in order that it will possibly resolve these programming duties without being provided the documentation for the API changes at inference time.
Large language models (LLM) have proven impressive capabilities in mathematical reasoning, but their application in formal theorem proving has been restricted by the lack of coaching information. Now the plain question that can come in our mind is Why ought to we learn about the latest LLM traits. I'm fantastic. I do not know what is going on, but I am fantastic. Roon, شات ديب سيك who’s famous on Twitter, had this tweet saying all the folks at OpenAI that make eye contact started working right here within the last six months. After all, whether DeepSeek's fashions do ship actual-world financial savings in vitality remains to be seen, and it's also unclear if cheaper, extra efficient AI could lead to extra individuals using the model, and so an increase in overall power consumption. These controls are expected to significantly enhance the prices associated with the manufacturing of China’s most superior chips. There are increasingly players commoditising intelligence, not just OpenAI, Anthropic, Google.
That's the same reply as Google provided of their example notebook, so I'm presuming it's correct. Make certain to put the keys for each API in the same order as their respective API. 5. Apply the identical GRPO RL process as R1-Zero with rule-based mostly reward (for reasoning duties), but additionally mannequin-based reward (for non-reasoning tasks, helpfulness, and harmlessness). By simulating many random "play-outs" of the proof process and analyzing the outcomes, the system can determine promising branches of the search tree and focus its efforts on these areas. It is a Plain English Papers summary of a research paper called DeepSeek-Prover advances theorem proving via reinforcement learning and Monte-Carlo Tree Search with proof assistant feedbac. The key contributions of the paper embrace a novel strategy to leveraging proof assistant suggestions and developments in reinforcement learning and search algorithms for theorem proving. The paper presents intensive experimental results, demonstrating the effectiveness of DeepSeek-Prover-V1.5 on a range of difficult mathematical issues. The paper presents the technical particulars of this system and evaluates its efficiency on difficult mathematical problems. I might like to see a quantized version of the typescript model I take advantage of for an extra efficiency enhance. Why have some international locations placed bans on the usage of DeepSeek?
If you beloved this article and you simply would like to collect more info with regards to ديب سيك i implore you to visit our web site.
- 이전글희망의 미래: 청년들의 비전 25.02.08
- 다음글15 Things You Didn't Know About Window Companies Milton Keynes 25.02.08
댓글목록
등록된 댓글이 없습니다.