Welcome to a new Look Of Deepseek
페이지 정보

본문
 DeepSeek LLM 67B Chat had already demonstrated significant efficiency, approaching that of GPT-4. Architecturally, the V2 models have been considerably totally different from the DeepSeek LLM series. The University of Waterloo Tiger Lab's leaderboard ranked DeepSeek-V2 seventh on its LLM ranking. Instability in Non-Reasoning Tasks: Lacking SFT knowledge for general dialog, R1-Zero would produce valid options for math or code but be awkward on easier Q&A or security prompts. R1-Zero has points with readability and mixing languages. 5. Apply the identical GRPO RL course of as R1-Zero with rule-based reward (for reasoning tasks), but in addition mannequin-based reward (for non-reasoning duties, helpfulness, and harmlessness). A similar process is also required for the activation gradient. 2. Apply the identical GRPO RL process as R1-Zero, adding a "language consistency reward" to encourage it to respond monolingually. Attempting to balance professional utilization causes specialists to replicate the same capacity. DeepSeek-V3-Base and DeepSeek-V3 (a chat mannequin) use essentially the same structure as V2 with the addition of multi-token prediction, which (optionally) decodes additional tokens quicker but much less accurately. However, its interior workings set it apart - specifically its mixture of experts architecture and its use of reinforcement studying and effective-tuning - which enable the mannequin to function extra effectively as it really works to provide persistently correct and clear outputs.
DeepSeek LLM 67B Chat had already demonstrated significant efficiency, approaching that of GPT-4. Architecturally, the V2 models have been considerably totally different from the DeepSeek LLM series. The University of Waterloo Tiger Lab's leaderboard ranked DeepSeek-V2 seventh on its LLM ranking. Instability in Non-Reasoning Tasks: Lacking SFT knowledge for general dialog, R1-Zero would produce valid options for math or code but be awkward on easier Q&A or security prompts. R1-Zero has points with readability and mixing languages. 5. Apply the identical GRPO RL course of as R1-Zero with rule-based reward (for reasoning tasks), but in addition mannequin-based reward (for non-reasoning duties, helpfulness, and harmlessness). A similar process is also required for the activation gradient. 2. Apply the identical GRPO RL process as R1-Zero, adding a "language consistency reward" to encourage it to respond monolingually. Attempting to balance professional utilization causes specialists to replicate the same capacity. DeepSeek-V3-Base and DeepSeek-V3 (a chat mannequin) use essentially the same structure as V2 with the addition of multi-token prediction, which (optionally) decodes additional tokens quicker but much less accurately. However, its interior workings set it apart - specifically its mixture of experts architecture and its use of reinforcement studying and effective-tuning - which enable the mannequin to function extra effectively as it really works to provide persistently correct and clear outputs.
To establish our methodology, we start by creating an knowledgeable model tailor-made to a selected domain, akin to code, arithmetic, or general reasoning, using a mixed Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) coaching pipeline. In April 2023, High-Flyer announced it could kind a new research physique to discover the essence of synthetic general intelligence. They opted for 2-staged RL, as a result of they found that RL on reasoning knowledge had "distinctive traits" totally different from RL on common data. Exceptional Performance Metrics: Achieves excessive scores throughout various benchmarks, including MMLU (87.1%), BBH (87.5%), and mathematical reasoning duties. This launch has made o1-degree reasoning models extra accessible and cheaper. Expert fashions had been used as a substitute of R1 itself, for the reason that output from R1 itself suffered "overthinking, poor formatting, and excessive length". The Financial Times reported that it was cheaper than its peers with a worth of 2 RMB for every million output tokens. What's the max output era limit? Several international locations have moved to ban DeepSeek’s AI chat bot, both completely or on authorities units, citing safety concerns. The United States thought it could sanction its option to dominance in a key know-how it believes will help bolster its national security. It’s very much like apps like ChatGPT, but there are some key differences.
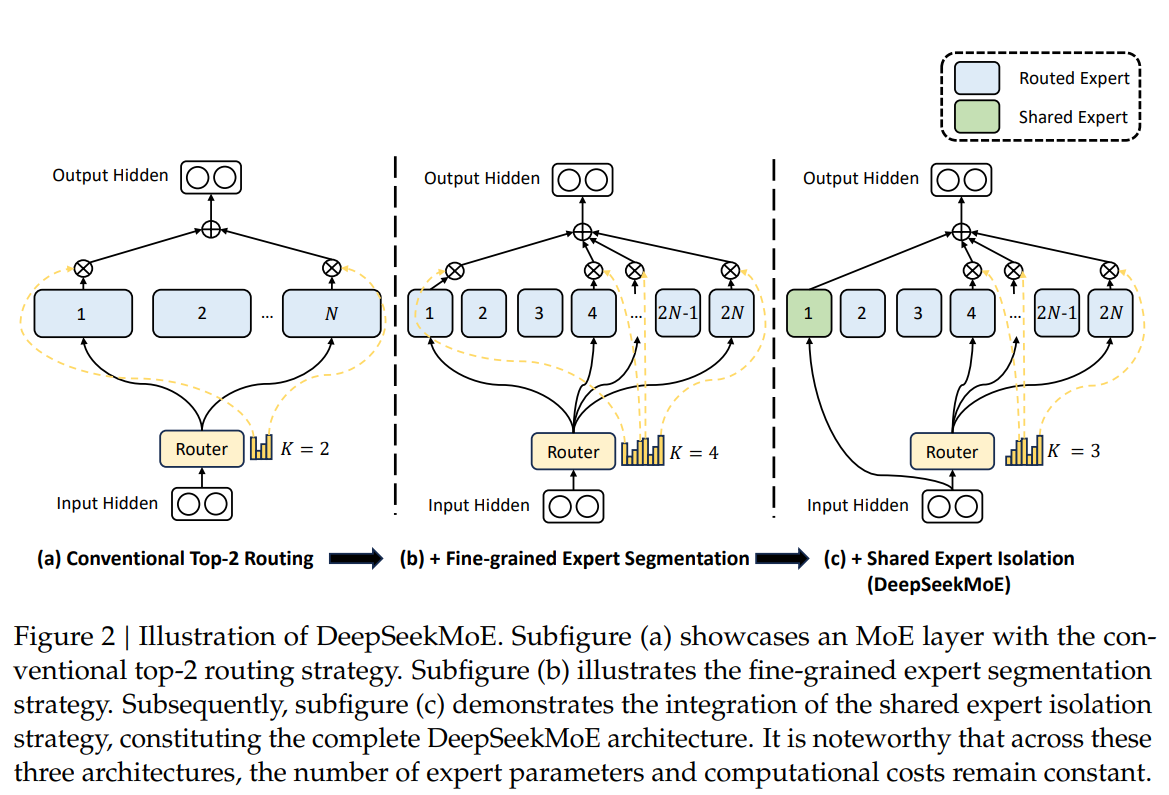
Qwen and DeepSeek are two representative model series with robust assist for each Chinese and English. 1. Pretrain on a dataset of 8.1T tokens, using 12% extra Chinese tokens than English ones. 1. Pretraining on 14.8T tokens of a multilingual corpus, largely English and Chinese. As a Chinese AI company, DeepSeek operates under Chinese laws that mandate knowledge sharing with authorities. DeepSeek-R1-Distill fashions had been as a substitute initialized from different pretrained open-weight models, together with LLaMA and Qwen, then high quality-tuned on synthetic knowledge generated by R1. It was designed to compete with AI models like Meta’s Llama 2 and confirmed higher efficiency than many open-source AI models at that time. However, management principle - particularly disruption concept - could have predicted that a challenger like this could inevitably come along. Remove it if you do not have GPU acceleration. Accuracy reward was checking whether a boxed reply is right (for math) or whether or not a code passes checks (for programming). DeepSeek claimed that it exceeded efficiency of OpenAI o1 on benchmarks resembling American Invitational Mathematics Examination (AIME) and MATH. Specifically, on AIME, MATH-500, and CNMO 2024, DeepSeek-V3 outperforms the second-greatest mannequin, Qwen2.5 72B, by approximately 10% in absolute scores, which is a substantial margin for such challenging benchmarks.
Should you loved this short article and you would like to receive much more information about شات DeepSeek assure visit the internet site.
- 이전글새로운 시작의 계절: 변화와 성장 25.02.10
- 다음글희망의 선물: 어려운 순간에서 찾은 희망 25.02.10
댓글목록
등록된 댓글이 없습니다.